| nextnano.com nextnano³ Download | Search | Copyright | Publications * password protected |
nextnano³ software
|
|
| 1D LDOS |
|
|
|
|
|
nextnano3 - Tutorialnext generation 3D nano device simulator1D TutorialLocal density of statesAuthors: Stefan Birner If you want to obtain the input files that are used within this tutorial, please
check if you can find them in the installation directory. Local density of states
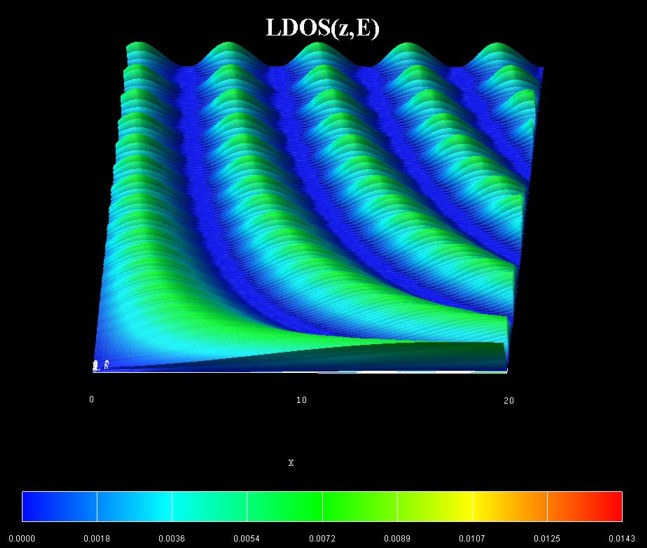
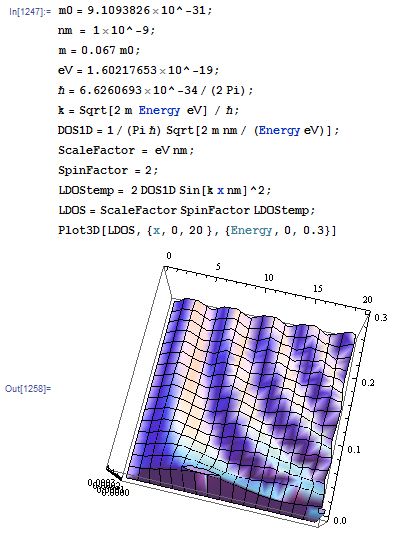
Here, we calculate the local density of states LDOS(z,E) for a
one-dimensional system of GaAs which is restricted to z > 0 nm. This LDOS can be derived analytically and reads
where k = (2m*E)1/2 / hbar. The following figure shows the calculated LDOS1D(z,E) for z = [0
nm, 20 nm] and E = [0 eV, 0.3 eV].
The local density of states output LDOS(z,E) is contained in these files:
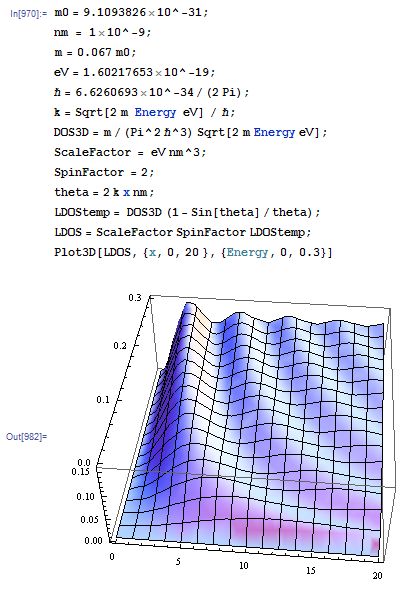
Local density of states for a 3D system restricted to z > 0 nmThe following plot is based on Fig. 1.11 (p. 30) of
|
|
|